TechnologyNLP
July 04, 20262 min read1 view
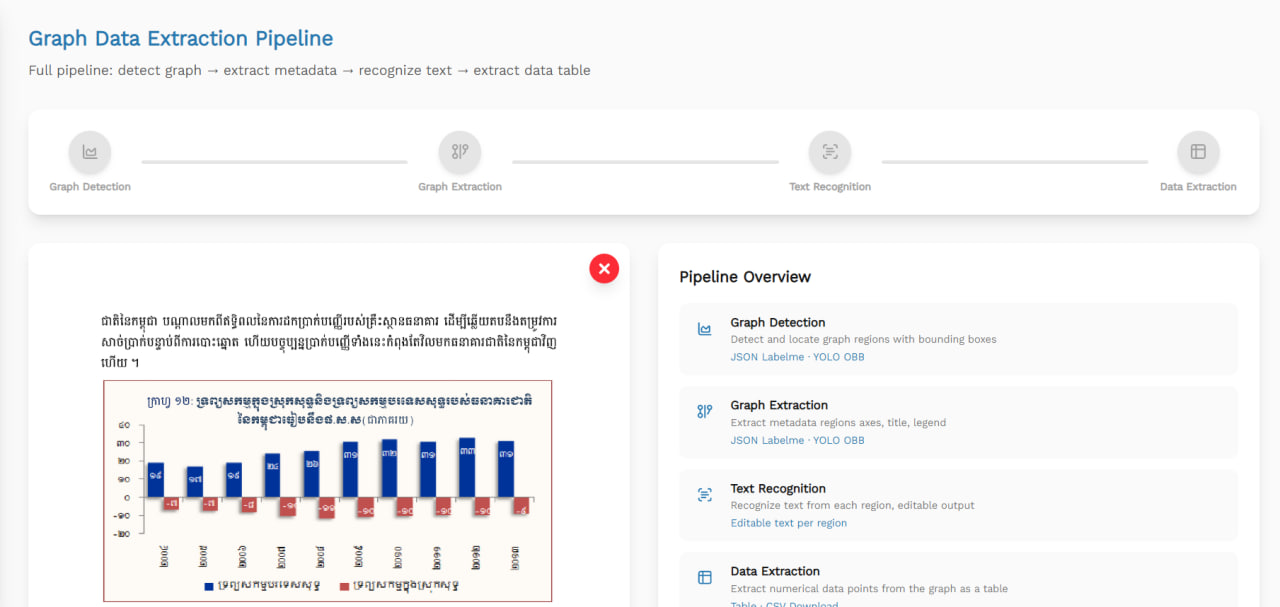
Graph Detection Model
Automated ingestion of scientific documents is notoriously difficult due to the visual complexity of academic layouts. Standard text extraction engines often try to parse entire pages linearly, treating graphs, charts, and diagrams as scrambled text or irrelevant noise. To prevent these processing errors, document pipelines must first identify and isolate non-text regions. The newly released YOLO model addresses this structural bottleneck by automatically localizing figures and plots directly from page images.
Read more