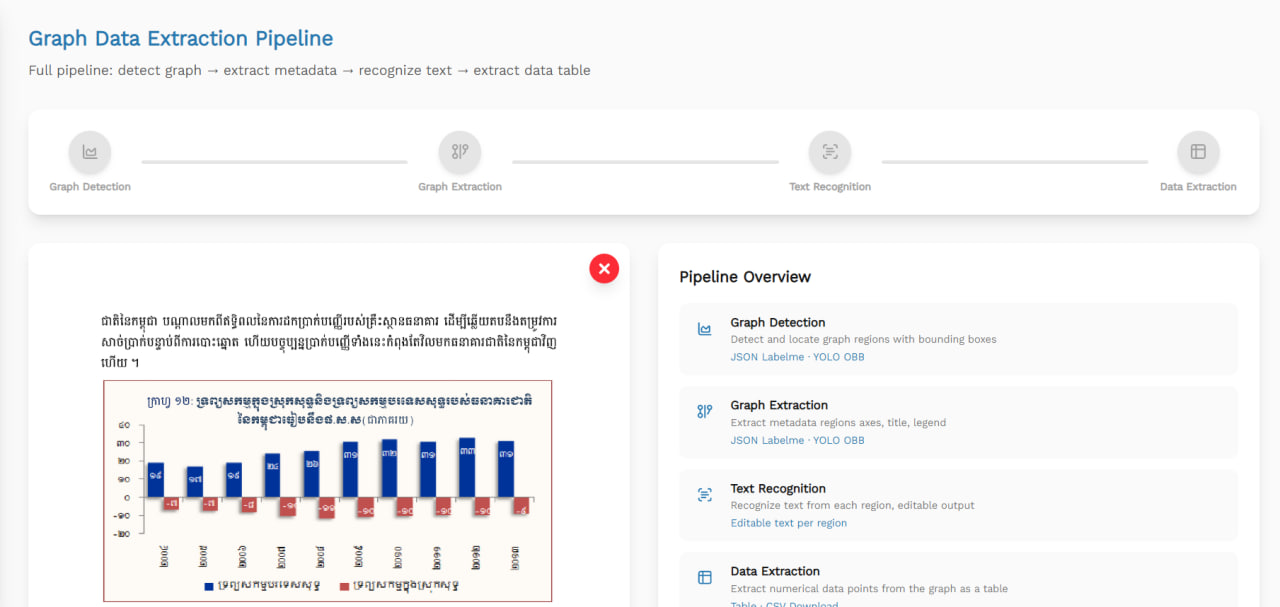
Automated ingestion of scientific documents is notoriously difficult due to the visual complexity of academic layouts. Standard text extraction engines often try to parse entire pages linearly, treating graphs, charts, and diagrams as scrambled text or irrelevant noise. To prevent these processing errors, document pipelines must first identify and isolate non-text regions. The newly released YOLO model addresses this structural bottleneck by automatically localizing figures and plots directly from page images.
YOLO-Powered Figure and Graph Detection in Scientific Documents
Automated ingestion of scientific documents is notoriously difficult due to the visual complexity of academic layouts. Standard text extraction engines often try to parse entire pages linearly, treating graphs, charts, and diagrams as scrambled text or irrelevant noise. To prevent these processing errors, document pipelines must first identify and isolate non-text regions. The newly released YOLO model addresses this structural bottleneck by automatically localizing figures and plots directly from page images.
Fine-Tuning for Layout Complexity
The model has been fine-tuned on a custom dataset specifically compiled to capture diverse scientific layouts and chart styles. By optimizing the underlying object detection architecture, the system balances rapid inference speeds with precise boundary localization. It successfully distinguishes charts and figures from surrounding dense multi-column text, legends, and formulas. This targeted training ensures that the model can be used for batch-processing massive archives of scanned literature without introducing significant computational overhead.