Extracting data from document tables is notoriously difficult because standard OCR often merges columns and scrambles grids. The Table Layout Detection tool, hosted on Hugging Face Spaces, uses deep learning to locate table boundaries and map individual row and column structures.
Table Layout Detection: Unlocking Scanned Tabular Data
While modern optical character recognition is highly effective at reading continuous text, it frequently fails when encountering tables. Without a dedicated layout parser, the structured relationship between rows and columns is lost, rendering the extracted data useless for automated analysis. Retyping or manually reconstructing these tables is a major source of friction in data processing workflows.
Deep Learning for Table Grid Parsing
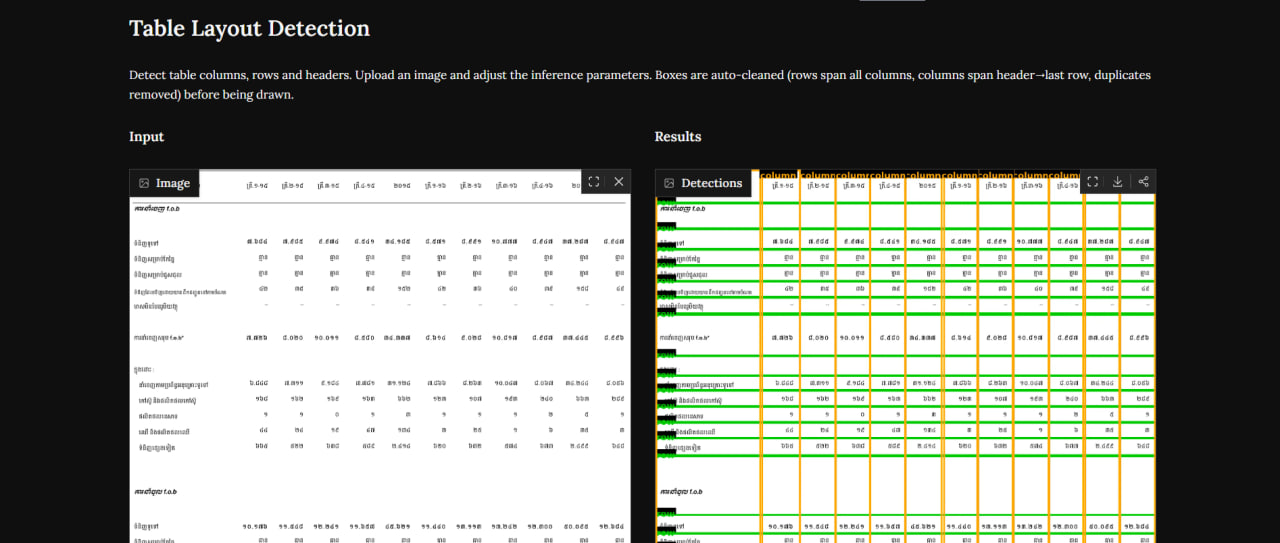
The application leverages specialized object detection architectures to analyze page layouts. When a document page image is uploaded, the model performs a dual task: first, it defines the overall bounding box of the table on the page, and second, it segmentally maps the interior lines, row dividers, column boundaries, and headers. By separating table structure recognition from character recognition, the tool ensures that cell data can be grouped logically prior to running OCR engines.
Interactive Testing and Practical Integrations
Deployed interactively on Hugging Face Spaces, this prototype allows developers to test model performance across various layouts, including bordered, borderless, and complex nested tables. Although handling dense tables with blank cells remains an area for active development, the current model provides an essential component for larger pipeline tasks like PDF-to-Excel conversion and semantic document parsing.