When parsing complex academic papers or financial reports, standard text-scraping tools often treat charts and graphs as unreadable noise. The Graph Detection model, hosted on Hugging Face Spaces, uses object detection to identify and isolate plot regions on a document page before text extraction begins.
Graph Detection: Segmenting Visual Data in Document Analysis
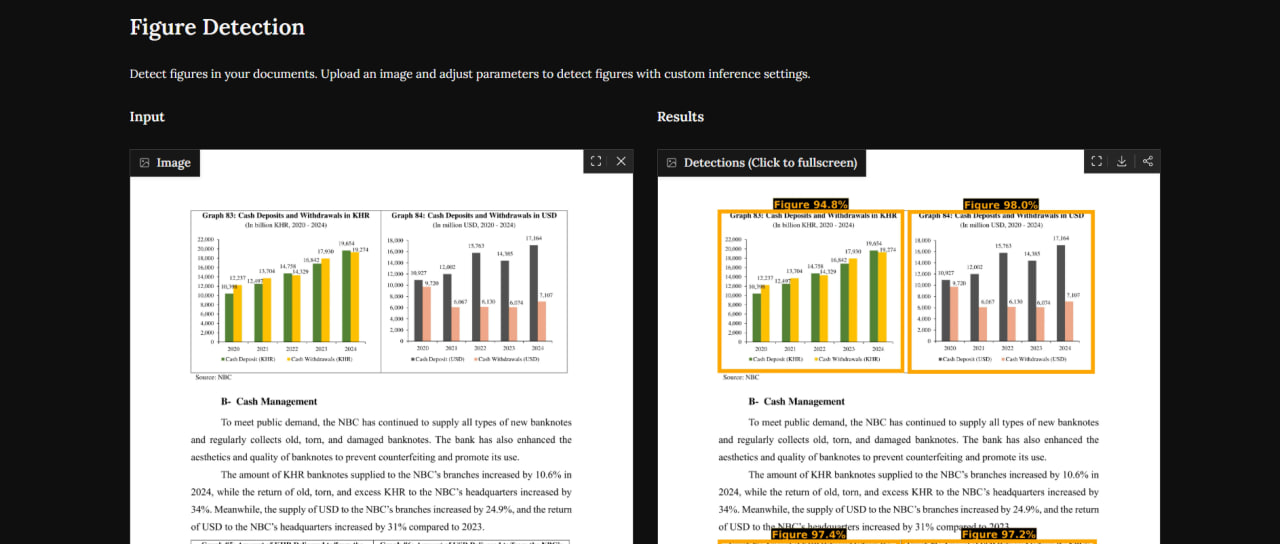
Multi-column document layouts present a major challenge for automated data pipelines. Reading engines often try to parse entire pages from top to bottom, which leads to garbled text when they inadvertently process bar charts, line plots, or diagrams. To avoid this, a preprocessing system must segment the document page, flagging and cropping graphical regions so they can be sent to specialized visualization analyzers instead of plain text engines.
Locating Charts with Object Detection
The Graph Detection app addresses this issue by deploying custom computer vision models trained specifically on document layout analysis datasets. When a document page is submitted, the model scans the visual hierarchy, isolating graph elements from surrounding text, headers, and tables. By placing precise bounding boxes around detected charts, the system allows pipelines to clean the text extraction layer and route the visual plots to downstream metadata parsing models.
A Foundation for Automated Chart Parsing
By exposing this model via an interactive Gradio space, the developer provides an accessible playground to evaluate how different document page configurations impact detection accuracy. While overlapping charts or hand-drawn figures still pose edge-case challenges, this segmentation tool serves as a critical first step. It ensures that standard text continues to OCR smoothly while graphical assets are directed to appropriate data recovery pipelines.