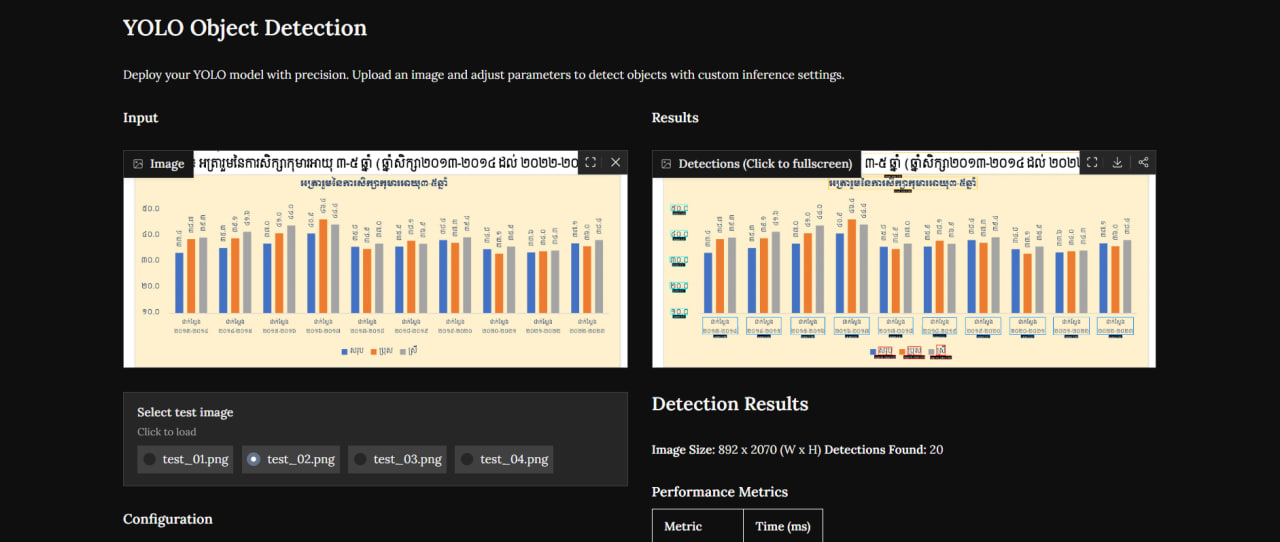
Extracting data from flat graph images is a tedious manual task that limits accessibility and searchability. The Graph Metadata Detection v2 application, hosted on Hugging Face Spaces, uses specialized computer vision and OCR to identify and parse critical graph elements like titles, legends, and axis labels.
Graph Metadata Detection: Parsing Visual Data into Structured Information
Charts and graphs are incredibly effective for visualizing data, but when saved as flat images in academic papers or business reports, the underlying numbers and contextual metadata are often lost to search engines and automated screen readers. Manually transcribing these components is time-consuming and prone to human error. Graph Metadata Detection v2 aims to resolve this bottleneck by automatically locating and extracting the structured text and bounding boxes of chart elements.
Under the Hood of Graph Parsing
The system relies on a multi-stage vision pipeline designed to analyze incoming chart images. First, an object detection model identifies the coordinates of crucial graph entities such as titles, x-axis labels, y-axis labels, legends, and data representations. Once these bounding boxes are established, a text recognition engine extracts the written characters, preserving the context of the visual representation. This metadata is then compiled into a structured format, enabling developers to map visual plots back to computational tables.