Digitizing complex scripts like Khmer remains a major barrier to historical preservation and data analysis. The Khmer OCR Tool tackles this by combining a modern Next.js and FastAPI stack with Gemini 2.5 Flash to automate printed and handwritten text extraction.
Khmer OCR Tool: Automating Text Extraction for Complex Scripts
The unique typographical characteristics of the Khmer language, such as stacked characters, subtle diacritics, and implicit word boundaries, make it difficult for standard optical character recognition systems to process accurately. This leaves many historical archives and administrative documents trapped in physical formats. To ease this transition into the digital age, a lightweight, web-based tool was developed to handle both printed and handwritten Khmer documents.
Designing a Modular, Decoupled Architecture
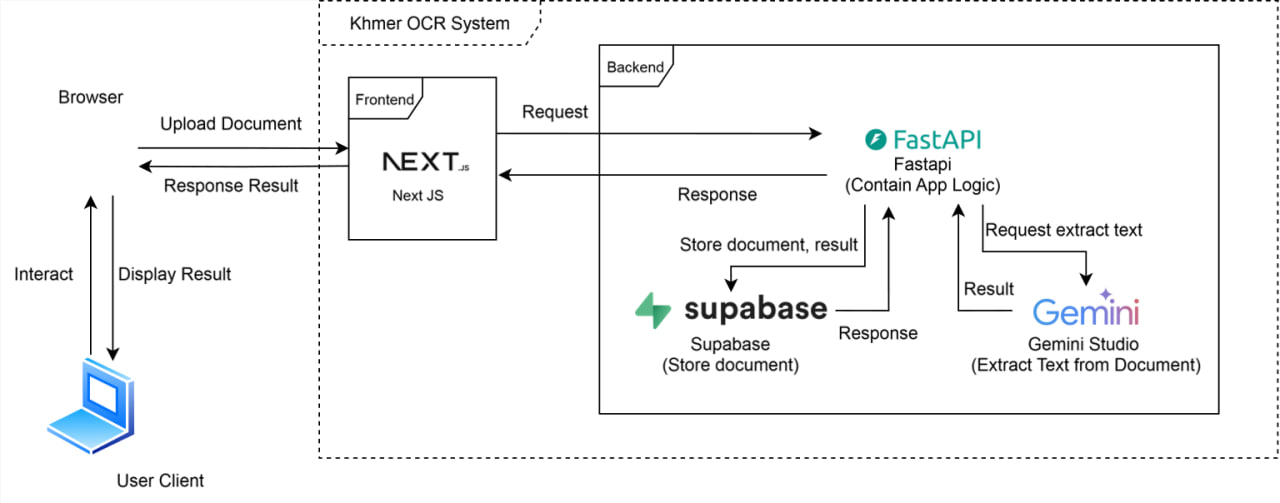
The system relies on a client-server structure to maintain low latency and independent scalability. The frontend, designed using Next.js, TypeScript, and Tailwind CSS, provides bilingual support for both Khmer and English. On the backend, a FastAPI server written in Python manages incoming requests and routes files to Supabase for secure cloud storage. Since the backend is deployed on a free tier of Render, a dedicated cron job was set up to ping the service regularly, preventing latency-inducing cold starts.
From Raw Image to Structured Text
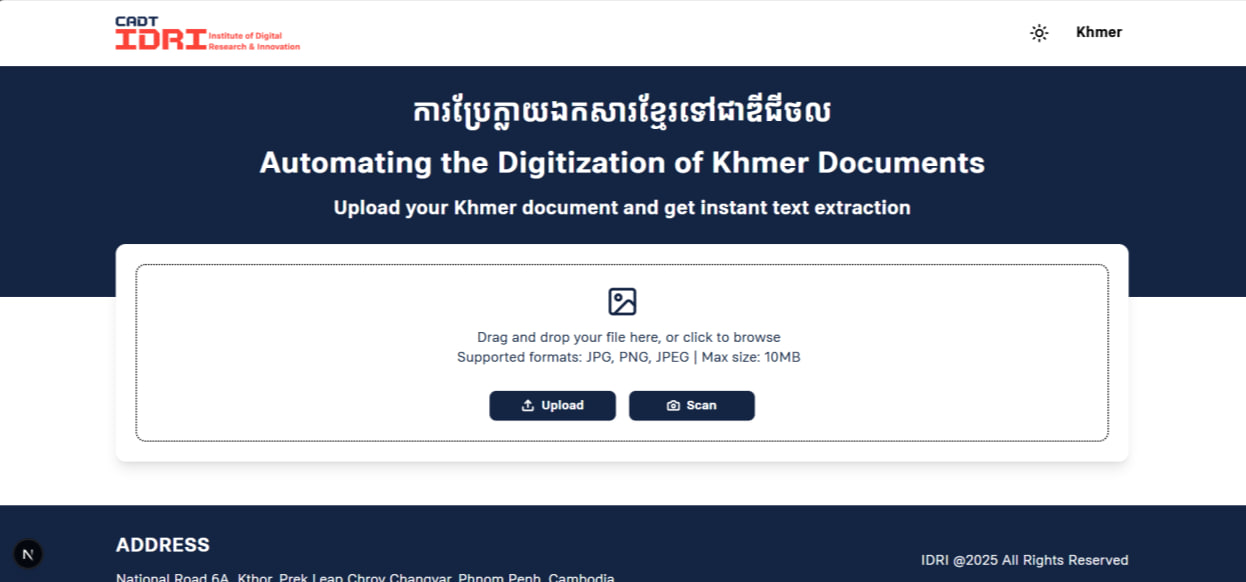
Users can submit files via standard drag-and-drop actions or capture images instantly using their device's webcam. Once validated, the image is passed to the Gemini 2.5 Flash API, which detects, translates, and structures the Khmer text. The digitized output is presented back to the user alongside the original input image for easy verification, complete with a confidence rating and a direct download option for plain text or JSON formats.
Development Challenges and Future Roadmap
Building the application required solving specific technical hurdles, including robust webcam stream termination on the frontend and navigating a learning curve in machine learning workflows. While the current pipeline utilizes generative AI for processing, future versions are designed to explore offline, script-specific models such as YOLO-based detection and TrOCR. This flexible architecture ensures that more specialized models can be integrated without requiring a complete rewrite of the existing system.